2-opt and 3-opt algorithms are used to get approximative solution of the travelling salesman problem. In the previous post I explained what the TSP problem is and I also included the implementation of Christofides algorithm.
# 2-opt algorithm
2-opt algorithm is one of the most basic and widely used heuristic for obtaining approximative solution of TSP problem. 2-opt starts with random initial tour and it improves the tour incrementally by exchanging 2 edges in the tour with two other edges.

In each step, 2-opt algorithm deletes two edges and , where are distinct , thus creating 2 subtours and reconnects the tour with edges and in case that the replacement reduces the length of the tour (Note: beware, that 2 edges cannot be incident to the same node). The final solution cost of the single 2-opt move can be expressed as
Algorithm ends in the local optimum, in which no further improving step is found. One two-opt move has time complexity of . In one two opt move in the worst case we need to check for one broke edge other edges that could be broken to improve the tour - thus the . We need to check it for all the edges, therefore we get the equation .
3-opt algorithm
3-opt algorithm works in the similar fashion. Instead of breaking the tour by removing 2 edges, it removes three edges, therefore breaking the tour into 3 separate sub-tours that can be reconnected in 8 possible ways (including the original tour) as shown on the following figure.
Let's assume that we got a tour that we split up to 3 different subtours. , , . There are 8 possible ways how to reconnect the original subtour ABC.
, , , , , , , (Note: Symbol ' defines the reversed segment).
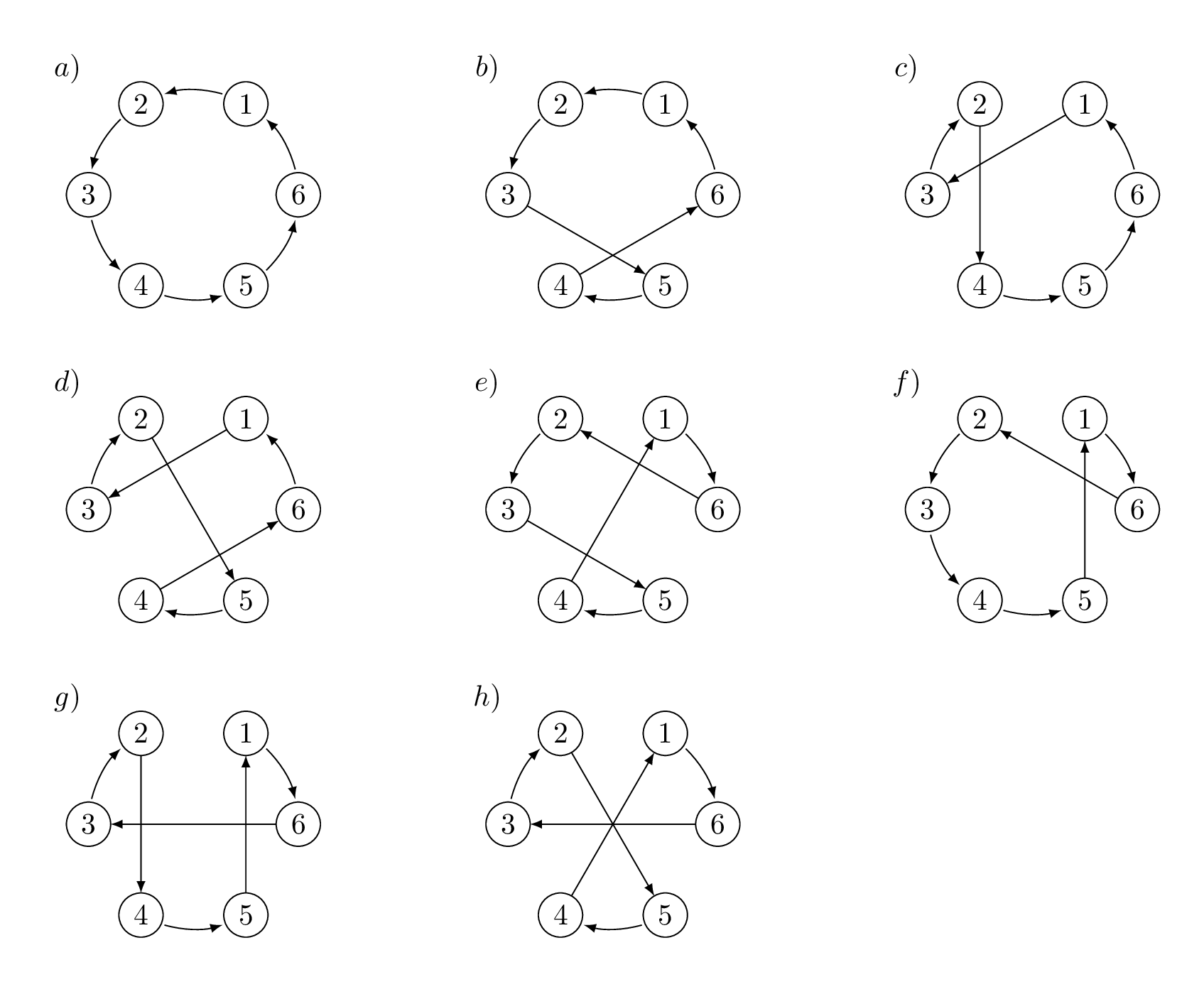
As you can see, there exists only 4 3-opt moves, namely , , and , is the original tour and the rest are 2-opt moves (one of three broken edges was reinserted back).
We will choose the best case from all 8 moves, particulary through one function:
def get_solution_cost_change(graph, route, case, i, j, k):
A, B, C, D, E, F = route[i - 1], route[i], route[j - 1], route[j], route[k - 1], route[k % len(route)]
if case == OptCase.opt_case_1:
return 0
elif case == OptCase.opt_case_2:
# second case is the case A'BC
return graph[A, B] + graph[E, F] - (graph[B, F] + graph[A, E])
elif case == OptCase.opt_case_3:
# ABC'
return graph[C, D] + graph[E, F] - (graph[D, F] + graph[C, E])
elif case == OptCase.opt_case_4:
# A'BC'
return graph[A, B] + graph[C, D] + graph[E, F] - (graph[A, D] + graph[B, F] + graph[E, C])
elif case == OptCase.opt_case_5:
# A'B'C
return graph[A, B] + graph[C, D] + graph[E, F] - (graph[C, F] + graph[B, D] + graph[E, A])
elif case == OptCase.opt_case_6:
# AB'C
return graph[B, A] + graph[D, C] - (graph[C, A] + graph[B, D])
elif case == OptCase.opt_case_7:
# AB'C'
return graph[A, B] + graph[C, D] + graph[E, F] - (graph[B, E] + graph[D, F] + graph[C, A])
elif case == OptCase.opt_case_8:
# A'B'C'
return graph[A, B] + graph[C, D] + graph[E, F] - (graph[A, D] + graph[C, F] + graph[B, E])
Then, after we get which case of reconnecting the tour is the best, we will need to reverse the segments accordingly:
if (i - 1) < (k % len(route)):
first_segment = route[k% len(route):] + route[:i]
else:
first_segment = route[k % len(route):i]
second_segment = route[i:j]
third_segment = route[j:k]
if case == OptCase.opt_case_1:
# first case is the current solution ABC
pass
elif case == OptCase.opt_case_2:
# A'BC
solution = list(reversed(first_segment)) + second_segment + third_segment
elif case == OptCase.opt_case_3:
# ABC'
solution = first_segment + second_segment + list(reversed(third_segment))
elif case == OptCase.opt_case_4:
# A'BC'
solution = list(reversed(first_segment)) + second_segment + list(reversed(third_segment))
elif case == OptCase.opt_case_5:
# A'B'C
solution = list(reversed(first_segment)) + list(reversed(second_segment)) + third_segment
elif case == OptCase.opt_case_6:
# AB'C
solution = first_segment + list(reversed(second_segment)) + third_segment
elif case == OptCase.opt_case_7:
# AB'C'
solution = first_segment + list(reversed(second_segment)) + list(reversed(third_segment))
elif case == OptCase.opt_case_8:
# A'B'C
solution = list(reversed(first_segment)) + list(reversed(second_segment)) + list(reversed(third_segment))
return solution
After that we reiterate the process until no improvements can be made.
Whole code can be found in Python on my github page. If you see any improvements can be made, feel free to post it into the comments or make PR directly!
PS: It is not in the scope of this post to describe the 3-opt fully. It is meant to provide the implementation and at least a little bit of description how the code is working. See [2] for more information on this topic.
Source:
[1] https://www.sciencedirect.com/science/article/abs/pii/S0377221799002842
[2] https://tsp-basics.blogspot.com/